Depth First Search
We return today to graph search. Last time we saw breadth-first search, today we're going to do depth-first search. It's a simple algorithm, but you can do lots of cool things with it. DFS is often used to explore the whole graph, and so we are going to see how to do that today. So high-level description is we're going to just recursively explore the graph, backtracking as necessary, kind of like how you solve a maze.
Let’s now consider a real world application of the DFS algorithm.
Number of Closed Islands - Problem Definition
Given a 2D grid consists of $0s$ (land) and $1s$ (water). An island is a maximal 4-directionally connected group of $0s$ and a closed island is an island totally (all left, top, right, bottom) surrounded by $1s$.
Return the number of closed islands.
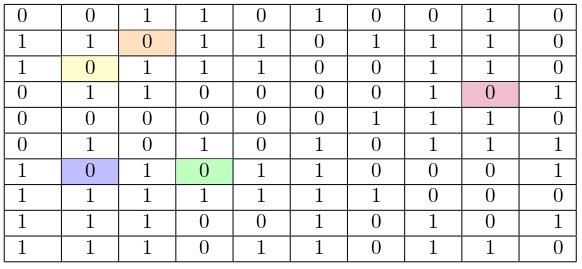
Output: 5

Output: 4
Note that closed islands are colored in the tables above.

Output: 2

Output: 1
Number of Closed Islands - Approach
We use the table $d$ to keep track of the discovery state of each block. We initialize each entry of the $d$ table to $false$, updating it to $true$ when we first discover that particular cell. We start off with the first undiscovered land block, finding all the reachable land blocks from that. If any of the reachable land blocks hit the border of the map area, then it is not surrounded by water, hence the procedure returns false. Otherwise, the land area reachable from the starting position is surrounded by water, thus true is returned. Each time we encounter a closed island, we increment the variable $k$ by one and finally return it. Also note that we should cover all the reachable land blocks from the starting block in one pass. What follows is the pseudocode of the procedure just described.
**Input:** Map area represented by an $m \cdot n$ matrix
**Output:** Number of closed islands.
$CLOSED-ISLAND(G)$
$\phantom{{}++{}}$ $m \gets G.length$
$\phantom{{}++{}}$ $n \gets G[1].length$
$\phantom{{}++{}}$ let $d$ be a $m \times n$ table
$\phantom{{}++{}}$ `for` $i = 1$ to $m$
$\phantom{{}++{}}$ $\phantom{{}++{}}$ `for` $j = 1$ to $n$
$\phantom{{}++{}}$ $\phantom{{}++{}}$ $\phantom{{}++{}}$ $d[i][j] \gets false$
$\phantom{{}++{}}$ let $k \gets 0$
$\phantom{{}++{}}$ `for` $i = 1$ to $m$
$\phantom{{}++{}}$ $\phantom{{}++{}}$ `for` $j = 1$ to $n$
$\phantom{{}++{}}$ $\phantom{{}++{}}$ $\phantom{{}++{}}$ `if` $G[i][j] == 0$ and $d[i][j] == false$
$\phantom{{}++{}}$ $\phantom{{}++{}}$ $\phantom{{}++{}}$ $\phantom{{}++{}}$ `if` $CLOSED-ISLAND-VISIT(G, d, i, j)$
$\phantom{{}++{}}$ $\phantom{{}++{}}$ $\phantom{{}++{}}$ $\phantom{{}++{}}$ $\phantom{{}++{}}$ $k \gets k + 1$
$\phantom{{}++{}}$ `return` $k$
**Input:** Map area represented by an $m \cdot n$ matrix, a discovery matrix $d$ with dimensions $m \cdot n$ and $x$ and $y$ coordinates of the land block.
**Output:** Whether the island rooted at the block lies in the position $i$ and $j$ is a closed island.
$CLOSED-ISLAND-VISIT(G, d, i, j)$
$\phantom{{}++{}}$ $d[i][j] \gets true$
$\phantom{{}++{}}$ $result \gets i \neq 1$ and $i \neq d.length$ and $j \neq 1$ and $j \neq d[1].length$
$\phantom{{}++{}}$ `for` `each` $p \in M$
$\phantom{{}++{}}$ $\phantom{{}++{}}$ $r \gets i + p[1]$
$\phantom{{}++{}}$ $\phantom{{}++{}}$ $c \gets j + p[2]$
$\phantom{{}++{}}$ $\phantom{{}++{}}$ `if` $r \gt 0$ and $r \le G.length$ and $c \gt 0$ and $c \le G[1].length$ and $G[r][c] == 0$ and $d[r][c] == false$
$\phantom{{}++{}}$ $\phantom{{}++{}}$ $\phantom{{}++{}}$ $result \gets CLOSED-ISLAND-VISIT(G, d, r, c)$ and $result$
$\phantom{{}++{}}$ `return` $result$
A sample implementation of the algorithm for finding the number of closed islands is given below.
Note that in the implementation section we used the non-short circuiting and operator, instead of the widely used short circuiting and operator. As mentioned before, we need to evaluate the blocks greedily, without immediately returning when we encounter a block which lies on the border of the map area. If you use the short circuiting and operator, then java would not bother to evaluate the right-hand operand if the left-hand operand evaluates to false.
Analysis
We have $O(m \cdot n)$ blocks in our map area. For each block, we find its four adjacent cells, check whether that position lies within the map area, and call the procedure recursively with the new coordinates if the current block is an undiscovered land area. Then we concatenate the results. This attributes to a constant amount of time for each block, given the number of adjacent cells is 4. Thus, our approach of finding the number of closed islands involves $O(m \cdot n)$ time.
Since we use the $d$ table with dimensions $m \times n$ to keep track of discovery status of each block, our solution incurs $O(m \cdot n)$ memory.


Comments
Post a Comment